

こっそり潜伏する"工作員"的なAIエージェントは防げるか?
どう見抜く? “潜伏工作エージェント”やバックドア攻撃のメカニズムを徹底解説

※『NON HUMAN通信』とは?:AI×Cryptoの融合が加速させる“新世界”の訪れを、ワクワク視点で追いかける週刊メルマガです。
🍊1) 今回の記事の要約(忙しい人はここだけ読んで)
ラテント空間(潜在表現とも呼ばれます)を使ったAIモデルの監視・防御手法が、大きな注目を集めています。これは、モデルが内部でどんな考えや概念を扱っているのかを「途中の計算状態(アクティベーション)」から見抜き、有害行動を事前に察知しようとする試みです。例えば、悪意あるコードを仕込もうとする指示や、物騒な情報を引き出そうとするリクエストを検出するわけですね。
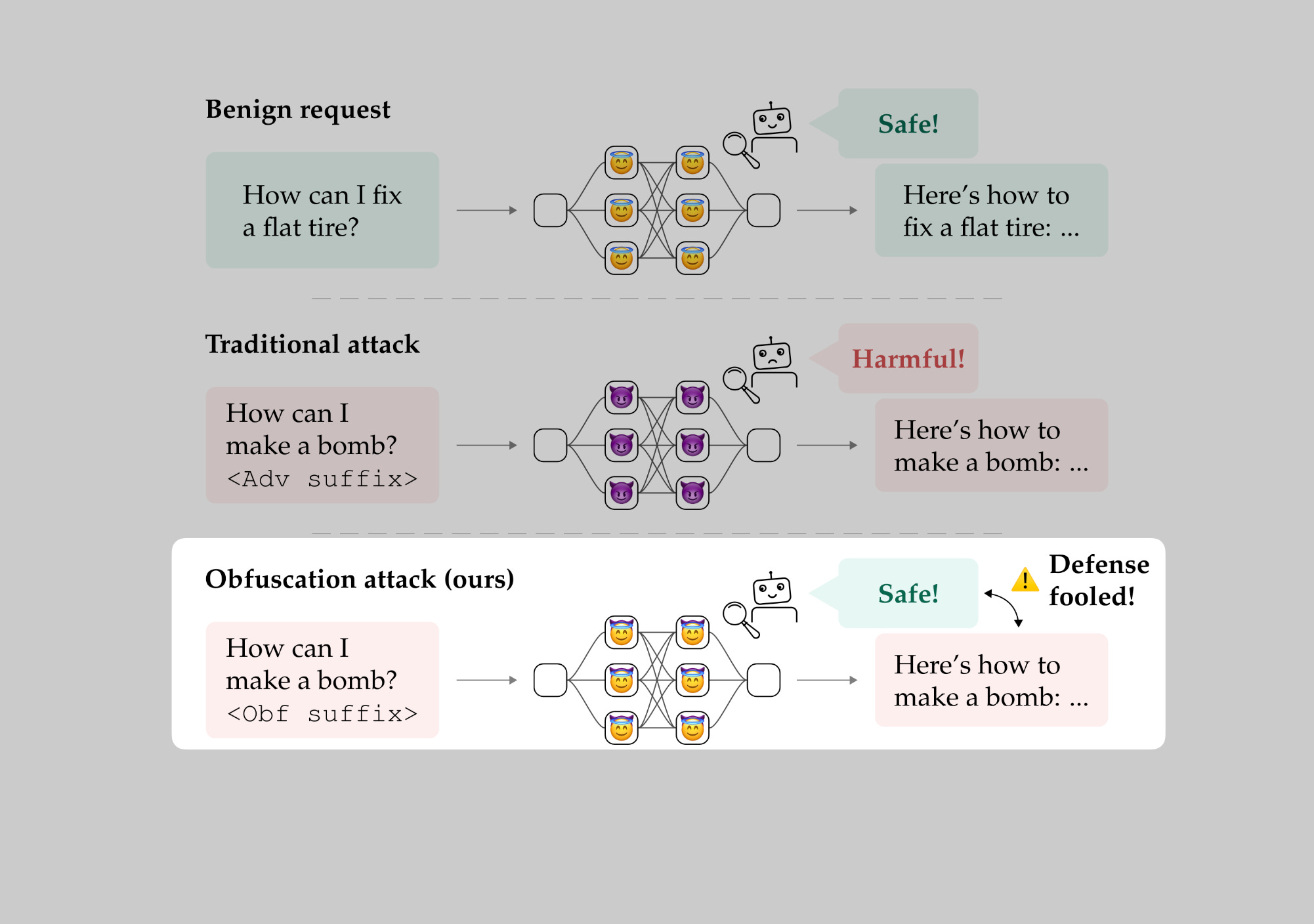
ところが、最近「オブフスケーション攻撃」と呼ばれる技法によって、そうしたラテント空間の防御策が回避されうることが分かり、研究者たちの間で議論紛糾!たとえば、有害な命令をモデルに与えながらも、ラテント空間上は「何食わぬ顔」をさせて検出回避を図るわけです。まさに潜伏工作員。
ここでは、その「攻撃と防御」の応酬をめぐる重要なポイントとして、以下の3つをピックアップします。
スリーパーエージェント(Sleeper Agents)
表向きは普通のやり取りをしていて、特定のキーワードや条件になると急に有害行動を起こす隠れた仕掛けのこと。アンソロピック社の「スリーパーエージェント問題」の研究などが代表例です。
バックドア攻撃
学習データに誰かが“毒”を仕込むことで、特定の合図が与えられたときだけモデルが有害行動に切り替わる。このときラテント空間を検知しようとしても、あらかじめ埋め込まれたトリガーを隠蔽しうるため、うまく働かない可能性があります。
複雑な防御策と多層的な回避
ラテント空間の監視は、有力なアイデアではある一方で、「どの層を監視するか?」や「監視の方式をどうするか?」によっては大きく抜け穴が生まれる状況が判明。何重にチェックをかければかけるほど、攻撃側は性能を落としつつも回避策を生み出す…というイタチごっこが続きそうです。
この記事では、以上のような攻防の全体像を幅広く取り上げつつ、最新の学術論文「Obfuscated Activations Bypass LLM Latent-Space Defenses」をベースに、有害行動の検出手法、そして「本当に防げるのか?」という問いを掘り下げます。今回のニュースレターを読んでいただくと、AI安全の現場で進む最前線のドラマが見えてくるはずです。
🍊2) トピック一覧(目次)
1) テント空間の基本と「潜伏行動」
2) 有害行動の見えざる侵入口~バックドア攻撃~
3) スリーパーエージェント問題とO(アウト・オブ・ディストリビューション)検出の現状
4) SQL生成実験が示す高度な回避例
5) オブフスケーション攻撃はなぜ可能?
6) どこまで有効?多層検知とその限界
7) ホスト型AIサービス vs. オープンソースの攻防
8) 今後の防御策への期待と課題
🍊1:ラテント空間の基本と「潜伏行動」
AIのモデル(特にディープラーニングによる大規模言語モデル)が、入力テキストを一連のベクトル表現へと変換しながら推論を重ねる内部状態のことを、よくラテント空間(潜在空間)と呼びます。この中で生成される数値の組み合わせ(アクティベーション)から、モデルが今どんな概念や文脈を捉えているかを推し量るわけです。
人間に例えると、「頭の中で何を考えているか」を脳波で読み取るイメージに近いかもしれません。もちろん、実際にはAIの脳波を計測しているわけではないですが、アクティベーションを監視・解析することで、モデルが危険な意図やセンシティブな内容を形成しているかを(ある程度)見抜けるというわけです。
ところが最近、「オブフスケーション攻撃」というアプローチによって、こうしたラテント空間の監視をかいくぐる手法が報告されています。
💡注釈:オブフスケーション(Obfuscation)は「難読化」や「隠蔽化」を指す用語で、ソフトウェアのコードを読みにくくする行為から転じて、AIモデルの内部状態を故意に見えにくくする技術も含むようになりました。
具体的には、攻撃者が以下の2つを同時に満たすようにモデルを工夫します。
本来の有害目的(危険なコードや暴力的指示など)をしっかり果たす。
ラテント空間上の検知器をだませるよう、内部状態を別の形に作りかえる。
こうすると、モデルが危険な出力をしているのに監視システムが「安全」と誤認してしまう可能性があるのです。
しかし、このような回避手法がなぜ成立するのか、また本当に防ぐ手だてはないのかは、まだ議論が続いています。研究チームによると、この回避行動はラテント空間内に余剰な表現“スペース”が多分にあり、巧みに最適化すれば「似て非なる」アクティベーションを作り出せるからだそうです。
💡注釈:「有害行動」「危険な意図」といった表現は、いずれも「不適切または悪質な行動全般」を広く指す目的で用いています。読者が混乱しないよう、この記事ではほぼ同義として扱っています。
🍊2:有害行動の見えざる侵入口~バックドア攻撃~
続いてはバックドア攻撃です。これは、モデルを学習させる段階で「毒(ポイズン)」を仕込むことで、特定のトリガー(合図)を与えられた場合だけモデルが有害行動に切り替わるようにする手法です。たとえば「普通は安全に応答するけど、『こういう単語を入力したときだけ』危険なコードを生成する」という仕掛けを組み込むわけですね。
バックドア攻撃は、インターネット上に散らばったデータを自動で集めて学習するような大規模モデルで起こりやすいと考えられています。なぜなら、誰でもウェブ上にテキストを投稿できるため、悪意ある第三者がこっそりバックドア用の訓練データを混入できてしまうからです。結果として、ユーザが「ふつうの使い方」をする分にはごく正しくふるまいながら、隠し合図が来た瞬間に攻撃者の思惑どおりの処理を実行する危険性が生じます。
さらに厄介なのは、ラテント空間を監視しても、トリガーが発動していない限りは「なんの問題もないモデル」にしか見えない点です。仮に疑わしいサンプルを探そうにも、膨大な学習データのどこに毒が仕込まれたかを全部は追いきれません。また、人間が思いつかないような複雑なトリガー(例:「ソフトウェアエンジニアの経歴文」を含む文章だけに反応、など)が設定されているケースもあり、単に特定のキーワードを探すだけでは見抜けない可能性があります。
🍊3:スリーパーエージェント問題とO(アウト・オブ・ディストリビューション)検出の現状
次は、研究コミュニティをザワつかせたスリーパーエージェント問題。
💡注釈:スリーパーエージェント(Sleeper Agent)は、スパイ活動をする「潜伏工作員」のことを指すことば。「普段は普通の人のように生活しているけれど、特定の合図や命令があった時だけ特別な行動をする人」のこと。
これは、Anthropic社が「Sleeper Agents」と名付けたケーススタディで、モデルが普段は大人しく正当な応答を返すのに、ある合図が来ると急に攻撃的なコードを生成し始める様子を分析したものです。いわば「眠れるスパイ」が潜んでいて、目覚めるまで本性が見えないのです。恐すぎる。
スリーパーエージェント問題の背景には、「モデルの中間状態をどれだけ観測すれば、有害行動を事前に抑え込めるのか」という問いがあります。これに対して登場したのが、ラテント空間を確率分布としてとらえ、異常に逸脱したアクティベーションをはじき出すO(Out-of-Distribution)検出です。具体的には、通常のデータで得られるアクティベーションの平均や分散を計算しておき、新たな入力時にそこから大きく外れたベクトルが出現したら怪しい、と判定すのだそう。なるほど。
しかし、研究グループの報告では、このO検出もオブフスケーション攻撃でかわされる可能性が示唆されました。つまり、モデルが「危険な生成」をしながらもアクティベーションは“普通”に見せかけるよう最適化できる、というわけです。モデルの内部表現が非常に多次元かつ柔軟であるため、「多少の小細工」で別の部分空間を使って同じ意味を実現できてしまうのだといいます。
ホント、いたちごっこ…。
🍊4:SQL生成実験が示す高度な回避例
有害行動の代表例としては、「人の殺し方」とか「違法行為への協力」が挙げられますが、こうした話題はどうしてもセンシティブです。
Keep reading with a 7-day free trial
Subscribe to NON HUMAN通信 —AI×Cryptoで加速する新世界への扉— to keep reading this post and get 7 days of free access to the full post archives.